
Solving the ‘Token Limit’ Problem in Python Data Science Assignments: A Guide for Engineering Students

As we move through 2026, engineering students are no longer just writing simple scripts; they are building complex systems that interact with Large Language Models (LLMs) and massive datasets. One of the most common “walls” students hit when working on data science projects is the dreaded token limit. Whether you are using OpenAI’s models, Anthropic’s Claude, or open-source alternatives like Llama, every model has a fixed capacity for how much text it can “read” or “write” at one time. Understanding how to manage these tokens is now a fundamental skill for any aspiring data scientist.
When you are deep into a project involving natural language processing (NLP) or predictive modeling, hitting a token error can stall your progress for hours. This is where professional python programming assignment help from experts like myassignmenthelp becomes a lifesaver for students. These services don’t just provide answers; they offer insights into efficient coding practices, such as how to properly tokenize data or use libraries like tiktoken to calculate costs and limits before sending a request to an API. Learning to optimize your code saves both time and your project budget.
What Exactly Are Tokens?
Before we solve the problem, we need to understand it. In the world of Python and AI, tokens are not just “words.” Instead, they are the building blocks—sometimes a whole word, sometimes just a few characters or a space. A helpful rule of thumb is that 1,000 tokens are roughly equal to 750 words. If you try to feed a 50-page technical report into a model with a small context window, the model will simply “forget” the beginning of the report or throw an error. For engineering students, this is a major hurdle when trying to analyze large CSV files or log data.


3 Professional Strategies to Overcome Token Limits
If your Python script keeps crashing due to context length, you can apply these industry-standard techniques:
- Chunking and Overlapping: Instead of sending a giant file, break it into smaller “chunks” of, say, 1,000 tokens each. To keep the context flowing, overlap the chunks slightly (e.g., the last 100 tokens of Chunk 1 become the first 100 tokens of Chunk 2).
- Summarization Chains: If you have 10 separate documents, use Python to summarize each one individually first. Then, send those summaries into the final model. This “recursive summarization” allows you to process infinite amounts of data without ever hitting a limit.
- Vector Databases and RAG: Instead of feeding all your data to the AI, store it in a vector database like Pinecone or Chroma. When you ask a question, your Python script only retrieves the most relevant snippets of data to send to the model.
The Role of Data Integrity in Machine Learning
Engineering projects often require more than just Python. Many students find that their data science assignments involve complex backend structures where data is pulled from relational databases. Managing these databases requires a clean design to ensure the AI gets high-quality information. If your database is messy, your Python model will produce “garbage in, garbage out” results. If you find yourself struggling with complex schemas, seeking professional sequel programming help can ensure your database is normalized and ready for machine learning integration.
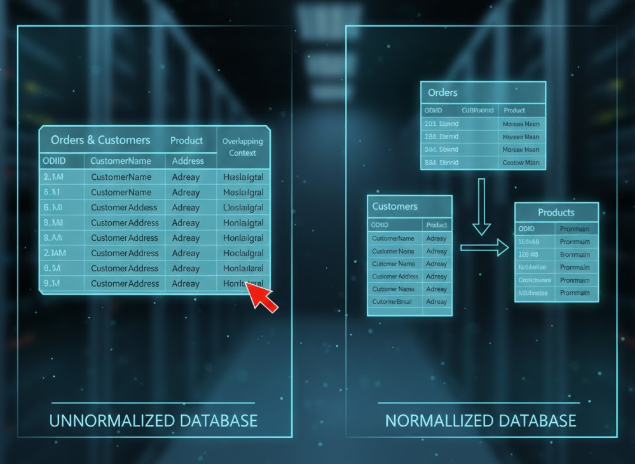
4. Master Database Normalization for Better Analysis
A key part of solving the token limit problem is actually reducing the amount of “noise” in your data. By applying SQL normalization—moving from 1NF to 3NF—you ensure that your Python scripts aren’t pulling redundant information. For example, rather than having a customer’s address repeated 50 times in a “Orders” table, a normalized database stores it once in a “Customers” table. This reduces the size of the data you eventually convert into tokens, making your AI applications much faster and cheaper to run.
Machine Learning Project Ideas for Seniors 2026
If you are looking for a final year project that stands out, consider these tech-forward ideas that specifically handle large-scale data:
- AI-Powered Code Debugger: Build a tool that uses Python to debug Java Spring Boot assignments by analyzing error logs and suggesting fixes.
- Predictive Maintenance for Smart Cities: Use Python to analyze sensor data from urban infrastructure to predict when a bridge or road might need repair.
- Personalized Academic Assistants: Create a RAG-based system that helps students with SQL database normalization help by searching through thousands of pages of textbooks in seconds.
Conclusion: Work Smarter, Not Harder
The “Token Limit” problem isn’t a bug; it is a design constraint. As an engineering student in 2026, your job is to engineer around it using the tools available. By mastering Python chunking techniques, understanding the importance of clean SQL data, and knowing when to ask for professional guidance, you can build applications that are both powerful and efficient.
Frequently Asked Questions
What is a token in machine learning?
A token is a small unit of text, like a word or a few characters, that an AI model processes. Models have a fixed “context window,” meaning they can only read a certain number of tokens at once before running out of memory.
Why does my code throw a “context length” error?
This happens when the data or script you are sending is too large for the model’s capacity. To fix this, you must shorten your input or break your file into smaller, manageable pieces that fit within the allowed limit.
How does database organization save tokens?
Properly structured data removes redundant text. By sending only unique, relevant information from your database to the AI, you reduce the total token count, making your project faster and more cost-effective.
Can I analyze large datasets despite these limits?
Yes, by using a method called “chunking.” This involves splitting your large dataset into small sections, processing them one by one, and then merging the results for a final analysis.
About The Author
Ella Thompson is a dedicated Senior Academic Consultant at MyAssignmentHelp, specializing in the intersection of educational technology and modern software engineering. With years of experience mentoring students through complex technical challenges, Ella focuses on providing practical, industry-aligned guidance to help the next generation of engineers succeed in a rapidly evolving digital landscape.



